Estimer le prix de son loyer avec Ruby et R
Attention: Papier pas du tout basé sur de vraies études scientifiques. En revanche, il n’a pas été testé sur des animaux.
Aujourd’hui, le quidam moyen dispose d’assez peu de moyen pour savoir si son loyer est juste ou si il est hors marché.
Je me suis posé la question de savoir comment résoudre ce problème. Vous pourrez trouver la méthode que j’ai employé dans cet article.
Ruby pour modéliser aisément ses données
Première étape: constituer un jeu de données valable. Idéalement, il faudrait avoir les loyer, les qualités de tous les appartements dans le quartier dans lequel se situe le bien qu’on veut estimer.
Je n’ai pas trouvé de méthode pour recueillir ces données à ce jour, alors je me suis rabattu sur les annonces de location des sites Particulier à Particulier et Le bon coin.
Mon idée de base était de constituer un jeu de donnée utilisable pour une régression linéaire. Pour cela, j’avais besoin de définir un set de variables ayant un sens dans le calcul du prix d’un loyer (surface, exposition, nombre de pièces, etc).
Je me doutais que je devrais ajouter des variables au cours de mon exploration des annonces immobilières (on ne peut pas penser à tout), et c’est donc pour cela que j’ai choisi de créer une classe avec un nombre dynamique d’attributs:
class Appartement
# FEATURES est notre références de variables:
FEATURES = [ :surface, :pieces, :loyer, :charges, :garage ]
# *FEATURES => chaque element du tableau devient un paramètre
attr_accessor(*FEATURES)
# On ajoute quelques valeurs par défaut lors qu'une absence
# de valeur ne signifie pas nil:
DEFAULTS= { garage: false, charges: 0 }
def initialize(params)
FEATURES.each do |feature|
value = params.fetch(feature) { DEFAULTS.fetch(feature) { NA } }
instance_variable_set("@#{feature}", value)
end
end
endA partir de cette classe, on peut commencer à recenser les cas qu’on rencontre dans les annonces dans un tableau:
APPARTEMENTS = [
{ surface: 47, pieces: 2, loyer: 890 },
{ surface: 18, pieces: 1, loyer: 640, cave: true, radiateur: 'electrique' },
# Moulte autres exemples ....
{ surface: 19, pieces: 1, loyer: 582, garage: true }
].map{|hash| Appartement.new(hash) }Vous noterez que j’ai ajouté les variables cave et radiateur à mes hashes ruby. Pour qu’ils soient exploitables dans le modèle, il suffit de les ajouter dans le tableau FEATURES.
Au final j’ai fini avec un tripotée de variables dans ma classe (présence d’un balcon, jardin, etc), et j’ai apprécié d’avoir fait ma classe aussi dynamique que possible.
Si on avait le courage, le temps et la motivation, on peut coder un crawler pour aller récupérer le contenu des annonces, mais comme ces dernières sont assez souvent rédigées en langage naturel, j’ai préféré perdre 30 minutes à les décortiquer à la main, et j’ai saisi une quarantaine d’entrées dans ma constante APPARTEMENTS.
Vient ensuite la question de l’exploitation de ces données. J’ai failli développer l’algorithme de régression linéaire à la main, car ruby, bien que se comportant comme une brouette du siècle dernier pour pas mal de chose, s’en sort plutôt bien quand il s’agit de calcul matriciel, mais j’ai plutôt choisi de porter mon choix vers R.
Pour pouvoir coller mes données dans R, j’ai juste ajouté le support de la méthode standard ruby de conversion en tableau (to_a) ainsi qu’une variable loyer_cc (loyer charges comprises):
# loyer charges comprises
def loyer_cc
charges == NA ? loyer : loyer + charges
end
# On ajoute le loyer charges comprises aux headers:
def self.headers
FEATURES + [ :loyer_cc ]
end
# Utilisé pour transformer les booléens en entier
REF_DATA = { true => 1, false => 0 }
def to_a
self.class.headers.map do |sym|
result = self.send(sym)
result == NA ? '' : REF_DATA.fetch(result) { result }
end
endEt ensuite, j’ai exporté mes modèles d’appartements au format csv:
require 'CSV'
CSV.open('appart.csv', 'wb') do |csv|
csv << Appartement.headers
NON_MEUBLES.each do |appart|
csv << appart.to_a
end
endOn finit ainsi avec un fichier appart.csv qui contient tout le jeu de données qu’on a modélisé en ruby.
R pour trouver un modèle d’estimation à partir de notre jeu de données
Une fois dans R, on charge le csv:
appart_data = read.csv("appart.csv")J’ai décidé à ce point de l’opération d’essayer de me débarrasser des artefacts. Pour cela, j’ai estimé que le prix au mètre carré était un bon indicateur:
appart_data$loyer_per_sm = appart_data$loyer_cc / appart_data$surfaceJ’ai pu constater que la distribution ressemblait à une gaussienne callée sur un prix moyen au mètre carré avec un histogramme:
hist(appart_data$loyer_per_sm)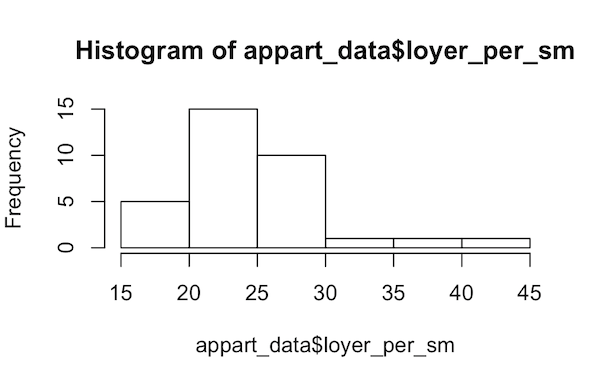
On peut ainsi se faire une première idée du prix au mètre carré dans le quartier (soit 24, au pifomètre, pour l’histogramme ci-dessus.
Si on peut aller un poil plus loin dans notre estimation, on peut calculer notre modèle de régression linéaire. Pour cela, il faut commencer par choisir les variables qu’on souhaite utiliser. Dans mon cas, j’ai choisi d’utiliser la surface, le nombre de pièces, la nature des radiateurs, la présence d’une terrasse et d’un garage comme critères:
m <- lm(loyer_cc ~ surface + pieces + radiateur + terrasse + garage, data = appart_data)Je viens ainsi de calculer un modèle de régression linéaire m qui me permet d’estimer le montant du loyer d’un appartement pour lequel je n’ai que les éléments suivants:
- La surface est de 42 mètres carrés
- Le chauffage est individuel et au électrique
- Il y a deux pièces
- Il n’y a ni terrasse ni garage
Et cela se fait de la manière suivante:
predict(m, list(surf=42, t= 2, rad = "electrique", terrasse = 0, garage = 0))La valeur que me retourne R est le montant estimé du loyer (charges comprises), en fonction du modèle que j’ai calculé auparavant.
Une étape interessante à ajouter avant celle la est celle de nettoyage des données, où l’on retire les actefacts en supprimant les appartements donc le prix au mètre carré est trop éloigné du prix au mètre carré médian.
Conclusion
Vous voila désormais paré pour estimer au gros point un loyer.
En revanche, au delà du plaisir que j’ai eu à pratiquer cette étude technique, il faut être conscient qu’elle est très probablement fausse, car les annonces qui sont disponibles le plus longtemps sont aussi probablement celles qui ont le moins de chances d’être pourvues (car trop chères, ou mal situées). C’est ce qu’on appelle le biais du survivant.
L’idéal serait de pouvoir pratiquer la même étude en se basant plutôt sur le loyer effectif que les gens payent, mais malheureusement, cette information est plus difficile à trouver (Le centre des impôts, c’est toi que je regarde…). On peut néanmoins tenter de compenser ce biais en prenant quelques exemples parmi ses amis pour faire une estimation du loyer avec notre modèle, et en déduire un coefficient de correction en comparant nos estimations avec ce qu’ils payent en réalité.